
Recent Posts
Archives
Tags
- Computer Vision
- 비전공자를 위한 HTML/CSS
- CodeUp6013
- Semi Supervised Learning
- CodeUp6012
- Segmentation Map
- Maximum Mean Discrepancy
- Domain Adaptation
- Contrastive Domain Discrepancy
- Vision Transformer
- Pseudo Label
- Consistency Regularization
- CodeUp6014
- CVPR2021
- ICLR2021
- ViT
- Attention
- CodeUp6016
- 백준
- transformer
- CodeUp6015
- Baekjoon
- ComputerVision
- Feature Augmentation
- Python
- 이것이 취업을 위한 코딩테스트다
- CodeUp
- Class Aware Sampling
- CodeUp6011
- 코드업
Link
IT 정리용 블로그!
[논문] Semi-Supervised Semantic Segmentation with Cross Pseudo Supervision 설명, 정리 본문
Computer Vision
[논문] Semi-Supervised Semantic Segmentation with Cross Pseudo Supervision 설명, 정리
집가고시퍼 2021. 7. 19. 17:18- Introduction
Semantic segmentation은 픽셀 단위의 training data labeling이 필요하기 때문에 다른 computer vision task보다 비용이 많이 든다. Semi-supervised semantic segmentation에는 Consistency regularization을 많이 사용한다. 이것은 다양한 변화(augmentation 등)에도 예측결과의 일관성을 가져다준다. Self-training도 많이 연구되고 있는데, labeled image에서 train된 segmentation model에서 unlabeled image를 이용해 pseudo segmentation map을 얻고, 이를 training data를 늘리고, segmentation model을 만들기 위해 사용한다.
본 논문에서는 network perturbation을 통한 consistency regularization 방법을 제시한다(pseudo supervision). 이 방법은 동일한 구조를 가졌지만 다르게 초기화된 두 segmentation network에 labeled image와 unlabeled image를 넣는다. Labeled image는 두 네트워크를 거쳐 각각 ground truth segmentation map을 이용해 supervise된다.
핵심은 두 네트워크에서 consistency를 만들도록 하는 cross pseudo supervision에 있다. 각 segmentation network는 input image를 입력 받으면 pseudo segmentation map을 리턴한다. pseudo segmentation map을 사용해 다른 segmentation network를 supervise하는데 사용한다. 이를 통해 두개의 다르게 초기화된 네트워크가 동일한 input에 대해 consistent하게 하고, prediction decision boundary가 low-density region에 위치하도록 한다. 마지막 optimization stage에서는 pseudo segmentation이 평범하게 labeled data로만 supervised training하는 것보다 좋은 결과를 낸다. - Related Works
1. Semantic segmentation
대부분의 접근법은 fully convolutional network(FCN)을 이용하고, 세 측면에 집중한다(resolution, context, edge). Resolution enlargement는 classification network로 생긴 spatial loss를 중재하는 것을 다룬다.
2. Semi-supervised semantic segmentation
Consistency regularization이 많이 사용되는데, 이는 다양한 변형이 있을 때 prediction이나 intermediate feature의 consistency를 늘리려 한다. augment된 이미지들 간 consistency constraint를 줘서 decision function이 low-density region에 위치하도록 한다. Feature perturbation은 여러 디코더를 사용해 디코더의 출력들간 constistency를 만들려 한다. 한 이미지에 대해 다양한 perturbation을 가해 consistency를 만드는 방법과 달리, GAN기반의 방법은 labeled data의 ground truth segmentation map의 statistical feature과 unlabeled data의 예측 map의 consistency를 만들려 한다. statistical feature는 discriminator network에서 얻는데, discrimination network는 ground truth segmentation과 predicted segmentation을 구분하려 학습한다.
3. Semi-supervised classification
Data를 neighboring하는 것은 같은 class에 속할 확률이 높다. Desicion boundary는 low density regin에 위치하도록 한다. perturbed input들에 대해 비슷한 output과 분포를 만들어내도록 모델을 학습시킨다. - Approach
\(D^{l}\)이 N labeled image set, \(D^{u}\)가 M unlabeled image set이라 할 때, semi-supervised semantic segmentation task는 labled와 unlabeled image 모두를 사용해 segmentaion network를 학습하도록 한다.
우선 두 parallel segmentation network를 만든다. \(P_{1} = f(X;\Theta_{1})\)\ \ \ \ (1) , \(P_{2} = f(X;\Theta_{2})\)\ \ \ \ (2) 를 만든다. 이 둘은 같은 구조를 가지고 있고, 다른 weight(\(Theta_{1}\), \(Theta_{2}\))로 초기화된다. Input X는 동일한 augmentation을 적용했고, \(P_{1}과 P_{2}\)는 softmax normalization 후에 network output을 나타내는 segmentation confidence map이다. $$ X\rightarrow X\rightarrow f(\Theta_{1})\rightarrow P_{1}\rightarrow Y_{1} $$$$X\rightarrow X\rightarrow f(\Theta_{2})\rightarrow P_{2}\rightarrow Y_{2}\ \ \ \ (3)$$
\(Y_{1},Y_{2}\)는 predicted one hot label map으로, pseudo segmentation map으로 불린다.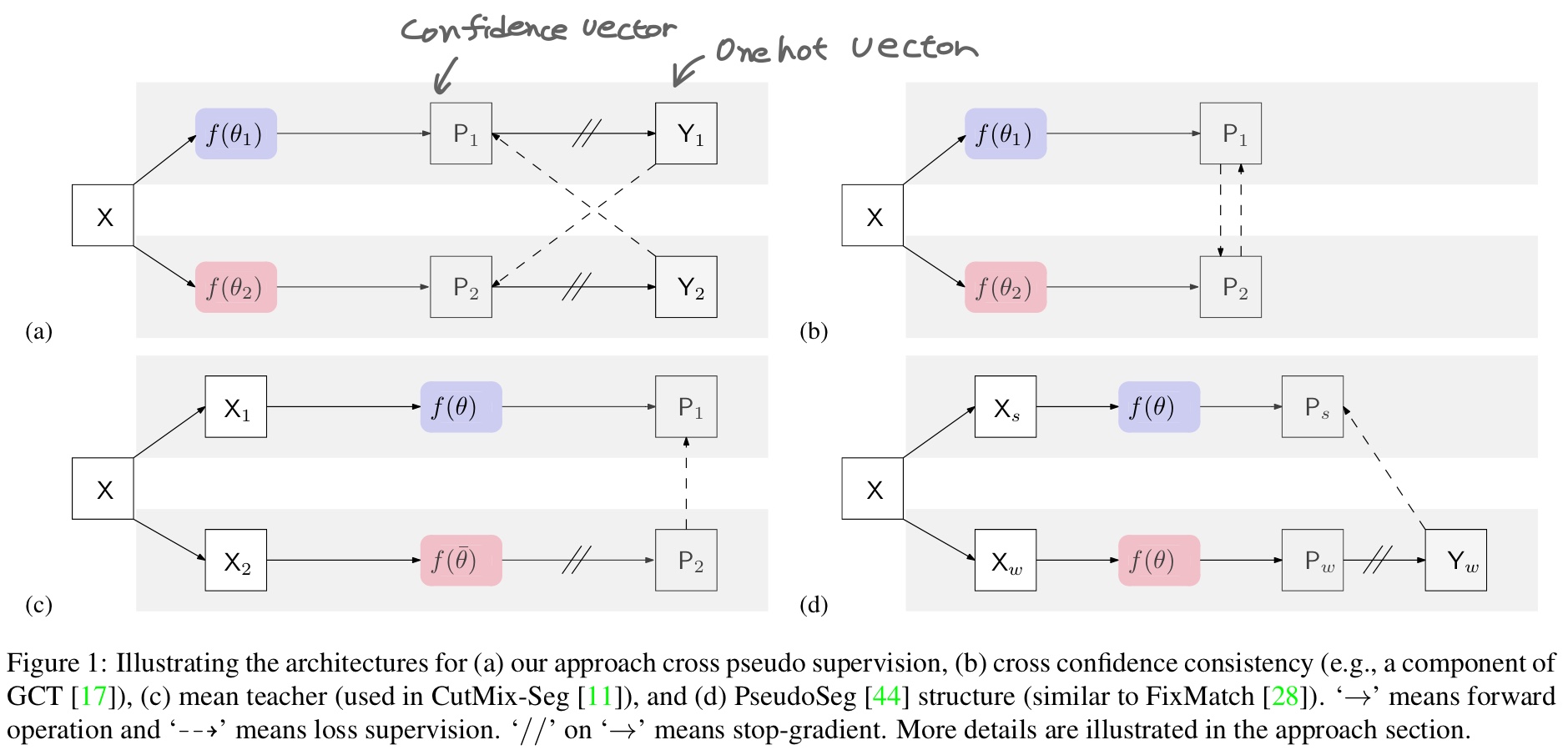
Fig 1
i번째 position에서, label vector \(y_{1i}, y_{2i}\)는 confidence vector \(p_{1i}, p_{2i}\)에서 얻은 one hot vector다. (3)에는 loss supervision을 포함하지 않았기에 이를 포함해준다.
Training에는 두가지 loss를 포함한다. supervision loss \(L_{s}\)와 cross pseudo supervision loss\(L_{cps}\)이다.
Supervision Loss \(L_{s}\)는 두 parallel segmentation network에 labeled image를 넣어 pixel wise cross entropyu loss를 사용해 얻는다. $$ L_{s} = \frac{1}{|D^{l}|}\sum_{X\in D^{l}}\frac{1}{W\times H}\sum_{i=0}^{W\times H}(l_{ce}(p_{1i},y_{1i}^{*})+l_{ce}(p_{2i},y_{2i}^*))\ \ \ \ (4) $$
Cross Pseudo Supervision loss는 bidirectional하다. 하나는 \(f_{\Theta_{1}}\)에서 \(f_{\Theta_{2}}\)로 간다. \(f_{\Theta_{1}}\)에서 얻은 Pixel wise one hot label map인 \(Y_{1}\) output을을 이용해 다른 네트워크 \(f_{\Theta_{2}}\)에서 얻은 pixel wise confidence map \(P_{2}\)를 supervise하는데 사용한다. 반대로도 마찬가지다. (Fig 1 -(a)) Unlabeled data에 대한 cross pseudo supervision loss는 (5)와 같다. $$ L_{cps}^{u} = \frac{1}{|D^{u}|}\sum_{X\in D^{u}}\frac{1}{W\times H}\sum_{i=0}^{W\times H}(l_{ce}(p_{1i},y_{1i}^{*})+l_{ce}(p_{2i},y_{2i}^*))\ \ \ \ (5) $$
Labeled data에 대한 cross pseudo supervision loss도 마찬가지로 구한다(\(L_{cps}^{l}\)). 최종적으로 cross pseudo supervision loss는 \(L_{cps} = L_{cps}^{l} + L_{cps}^{u}\)로 구한다. 그리고 최종 training objective는 다음과 같다. $$ L = L_{s} + \lambda L_{cps}\ \ \ \ (6) $$\(\lambda\)는 trade off weight다.
본 논문에서는 CutMix augmentation도 적용한다. 두 네트워크 \(f_{\Theta_{1}}\), \(f_{\Theta_{2}}\)에 cutmix된 이미지를 넣는다. CutMix에 사용할 두 source image를 각 segmentation network에 넣는다. 그리고 두 pseudo segmentation map을 mix해서 다른 segmentation network의 supervision에 사용한다. - Discussions
1. Cross Probability Consistency
두개의 perturbed network에 가하는 optional consistency. Pixel wise confidence map에서 온 probability vector들은 유사해야 한다(Fig 1-(b)). Loss function은 $$ L_{cpc} = \frac{1}{|D|}\sum_{X\in D}\frac{1}{W\times H}\sum_{i=0}^{W\times H}(l_{2}(p_{1i},p_{2i}^{*})+l_{2}(p_{2i},p_{1i}^*))\ \ \ \ (7) $$이다. Example loss는 \(l_{2}(p_{1i},p_{2i}) = \left \| p_{1i}-p_{2i} \right \|_{2}^{2}\)으로 consistency를 가하기 위해 사용된다. \(D\)는 labeled set \(D^{l}\)과 \(D^{u}\)의 union이다.
2. Mean teacher
다른 augmentation을 사용한 unlabeled image는 동일한 구조를 가진 두 개의 network(student \(f(\thteta)\), mean teacher \(f(\bar{\theta})\))로 들어간다. 파라미터 \(\bar{\theta}\)는 student network parameter \(\theta\)의 moving average다. $$ X\rightarrow X_{1}\rightarrow f(\theta)\rightarrow P_{1} $$$$X\rightarrow X_{2}\rightarrow f(\bar{\theta})\mapsto P_{2}\ \ \ \ (8)$$\(X_{1}\)과 \(X_{2}\)는 X의 다르게 augment된 version이다. Consistency regularization은 teacher network로 예측한 \(P_{2}\)와 student network의 \(P_{1}\)을 allign하려 한다. Train하는 동안, \(P_{1}\)을 \(P_{2}\)로 supervise하고 teacher network에는 back propagation을 가하지 않는다. \(\mapsto\)는 back propagation을 가하지 않는다는 의미로 사용했다. 이것은 Fig 1-(c)에 해당한다.
3. Single network pseudo supervision
본 논문에 제시된 downgrade 버젼인 single network pseudo wupervision을 생각해보자. 두 네트워크는 동일하다.

Fig 1-(d)
(10)은 Fig 1-(d)와 전체적으로 유사하지만, 1-(d)에서는 하나는 weak augmentation을, 하나는 strong augmentation을 해줬다. (9)에서 Y->P로 가는 화살표는 loss supervision을 나타낸다. 하지만 single network pseudo supervision은 성능이 좋지 않았다.
4. Pseudo Seg
Weakly augmented image \(X_{w}\)를 이용해 Pseudo segmentation map을 만들고, 이를 이용해 동일한 파라미터를 사용한 동일한 네트워크에서 strongly augmented image \(X_{s}\)를 넣어서 나온 output을 supervise하는데 사용한다(Fig 1-(d)). 동일한 이미지 X에 대해 strong augment, weak augment를 진행한다.Fig 1-(d)
\(Y_{w}\)에서 \(P_{s}\)로의 화살표는 loss supervision을 나타낸다. single network pseudo supervision과 유사하지만, 차이점은 pseudo segmentation map은 weak augmentation에서 왔고, 이 map이 strong augmentation에 대해 supervise한다는 점이다.
'Computer Vision' 카테고리의 다른 글
'Computer Vision' Related Articles
more



Comments