[논문] All Labels Are Not Created Equal: Enhancing Semi-supervision via Label Grouping and Co-training 설명, 정리
집가고시퍼
2021. 7. 25. 11:57
Introduction
Semi supervised Learning에 있어 어떤 접근법들은 consistency regularization에 집중하기도 한다. 이들은 동일한 unlabeled input 이미지를 변형한 버젼들에 대해 consistent한 prediction을 내리도록 한다. 반면, 다른 접근법들은 pseudo labeling에 집중하기도 한다. 여기서 모델은 unlabeled data에 대해 인공적인 label을 만들고, 이들을 이용해 train한다. 두 접근법을 섞어 사용하는 것이 SOTA를 보이기도 한다. Pseudo labeling에 있어, 흔히 일어나는 문제는 confirmation bias다. 모델은 잘못된 prediction을 이용해 학습을 진행하고, 여기서 에러가 누적되어 문제가 나타난다. 이 문제를 완화하기 위해, warm up phase를 도입해 모델이 안정적이게 될 때 까지 기다리기도 하고, 각 mini batch에서 pseudo label된 sample의 수를 제한하기도 한다. 혹은 confidence threshold를 도입해 모델이 매우 자신있을 때만 pseudo label을 활용하도록 한다. 하지만 이 해결방법들의 공통점은 model의 output에만 집중하고, class들 간의 잠재적인 유사성에 대한 prior knowledge에는 집중하지 않는다는 것이다. 유사한 class들은 model이 판단을 어려워 해 pseudo label이 잘 나타나지 않는다. 모델이 prediction에 대해 confident하지 못하기 때문에, 대부분의 유사한 sample들을 버리게 된다. 이러면 pseudo labeled pool에서 class 불균형이 일어나고, 학습에 문제가 생긴다.
본 논문에서는 class labels semantics를 이용해 class들 간의 유사성 문제를 해결한다. 이를 위해 본 논문에서는 두 방법을 제시해 label embedding을 만든다. label embedding은 class들 간의 유사성에 weak prior를 encode해준다. 이러한 embedding을 사용하면 class label을 시각적으로 유사한 concept들로 group할 수 있는 basis를 제공하고, 이런 grouping을 통해 pseudo labeling 결정을 내린다. label embedding의 이점은 label grouping을 넘어, 모델이 image feature을 더 의미있는 semantic space에 map하도록 하여 few shot transfer를 가능하게 한다. 본 논문에서는 SSL 성능을 높이기 위해 co-training approach를 사용한다. 두 classifier를 class label에 대한 두 개의 다른 시각(one hot, distributed)으로 학습시킨다. classifier 하나는 pseudo labeling 단계에서 label grouping을 사용하고, 다른 하나는 사용하지 않는다. 그리고 두 개의 classifier들이 unlabeled data들에 대해 consistency regularization loss를 사용해 그들의 차이를 학습하도록 한다.
Fig 1 요약하자면, 1. confusion event를 사용해 유사한 class들 간의 pseudo labeling quality를 높인다. 2. co-training based SSL 방식을 사용해 두 classifier의 class label에 대한 서로 다른 시각을 이용해 얻은 pseudo label을 이용해 서로 협력하도록 한다.
Background
1. Consistency Regularization 주어진 unlabeled image에 대해 몇가지 augmentation을 주고, 이들의 prediction들이 consistent하도록 loss를 사용한다.
2. Pseudo Labeling Unlabeled data에 대해 인공적인 label을 만들고, 이들을 이용해 학습한다. labeled example을 \(X = \left \{(x_{i},y_{i})\right \}_{i=1}^{n}\), unlabeled example을 \(U = \left \{u_{j}\right \} _{j=1}^{\mu\cdot n}\)이라 하자. \(\mu\)는 주어진 batch에서 unlabeled data와 labeled data의 비고, \(y_{i}\)는 one hot label이다. Pseudo labeling의 목적은 $$ L(\theta) = \frac{-1} {\mu\cdot n} \sum_{j=1}^{\mu n}\eta_{j}logp(y = \hat{y}_{j} | u_{j},\theta)\ \ \ \ (1) $$(1)을 최소화하는 것이다. \(\theta\)는 학습가능한 모델의 파라미터, \(\hat{y}\)는 pseudo label, \(\eta\)는 arbitrary function이다. \(\hat{y}\)와 \(\eta\)의 선택에 따라 pseudo labeling이 다르게 진행된다. 이 중에서 confident based method는 $$ \hat{y}_{j} = argmax_{y'}p(y=y'|u_{j},\theta)\ \ \ \ (2) $$1은 indicator function을 의미한다. 이 방법에선 모델의 confidence score가 prediction threshold(\(\tau\))를 넘겼을 때만 unlabeled sample이 pseudo labeling에 사용된다. 그리고 pseudo label은 가장 높은 score로 보인 class로 선택된다. 이 방법은 confirmation bias를 완화시킨다. 또한, entropy minimization을 장려하여 모델이 unlabeled data에 대해 높은 예측값을 내도록 한다.
3. Co-training 데이터에 대해 다른 시각을 가진 두 모델을 학습시킨다. 각 모델은 다른 모델의 가장 confident한 prediction을 통해 학습된다. 이들은 서로의 차이를 통해 학습된다. 본 논문에서는 데이터보다 label에 대한 두 가지 다른 시각을 사용한다. 하나는 one hot view고, 다른 하나는 distributed view(label embedding)이다. distributed view는 label을 image feature space에서 다른 semantic space로 map하는 능력을 가진다. label embedding은 label들 간 시각적 유사성을 파악하도록 학습된다.
Problem Statement and Motivation
Pseudo labeling에만 의존하는 접근법은 pseudo label을 만들 때 모델의 prediction에만 의존할 뿐, class 간의 유사성에 대한 prior 정보를 활용하지 않기 때문에 한계가 있다. 시각적으로 유사한 class들은 low confident prediction을 만들고, 이들은 폐기된다(FixMatch같이 일정 threshold를 넘지 못하는 경우). pseudo label이 붙여진 instance들은 class 불균형이 일어나고, SSL을 잘 이루어지지 못하게 한다. 이를 해결하기 위해 label similarity를 얻기 쉬운 essential prior로 고려한다.
Our Method(SemCo)
본 논문에서는 pseudo labeling에 class 유사성에 대한 prior knowledge 사용을 제안한다. Class들 간의 유사성을 label embeddings matrix \(M \in R^{K\times d}\)를 사용해 인코딩한다. \(M\)의 각 row는 class \(k \in \left \{1,...K\right \}\)의 d dimensional label embedding을 의미한다. Label을 group하기 위해 density based clustering approach(하이퍼파라미터 \(\epsilon\)을 사용해 group의 수가 사전에 정의되지 않도록 만드는 등)를 사용한다. 다음에는 Q개의 class group을 얻는다.
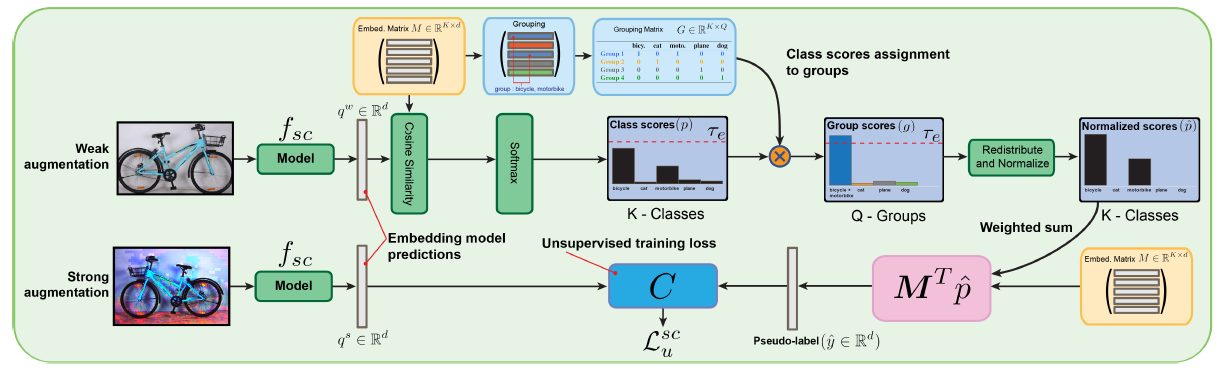
Fig 1 그리고 동일한 backbone 네트워크를 사용한 두 개의 classifier을 학습시킨다(Fig 1). Semantic classifier \(f_{sc} : R^{h\times w} \rightarrow R^{d}\)는 입력된 이미지를 M개의 row로 span된 embedding space에서 해당 샘플에 해당하는 라벨에 가깝게 map한다. 그리고 One hot classifier \(f_{oh} : R^{h\times w} \rightarrow R^{K}\)는 입력 이미지를 label의 one hot view에 map한다. \(f_{sc}\)와 \(f_{oh}\)는 동일한 backbone 네트워크와 파라미터를 가진다. 두 classifier에 대해 각각 labeled 데이터에 대해서는 supervised loss를 줄이고, unlabeled 데이터에 대해서는 consistency loss를 줄이려 한다. 추가적으로 co-training을 위한 loss term을 추가해 두 classifier가 pseudo labeling에서 협력하도록 한다.
Semantic Classifier
Supervised loss를 위해서는 실제 label embedding과 예측한 label embedding 간의 cosine loss를 줄이려 한다. $$ L_{s}^{sc} = \frac{1} {n} \sum_{i=1}^{n}C(M^{T}y_{i},f_{sc}(x_{i}))\ \ \ \ (3)\\ with C(z,z') = 1-CosineSim(z,z') $$ Fig 3. Unsupervised Loss Unsupervised Loss를 위해서는 pseudo label을 얻기 위해 weakly augmented 이미지를 사용하고, 이것을 동일한 이미지를 strong augment한 것에 대한 예측 결과와 enforce against한다. Unlabeled 이미지 \(u_{j}\)에 대해, 이미지를 약하게 augment한 것의 predicted embedding은 \(q_{j} = f_{sc}(A_{w}(u_{j}))\)이다. 그리고 \(q_{j}\)와 \(M\)간의 cosine similarity를 normalize함으로써 class score \(p_{j} = p(y_{j}|u_{j})\)을 계산한다. 만약 class 중 하나에 대한 예측 값이 threshold(\(\tau_{e}\))를 넘으면 unlabeled 샘플을 pseudo labeling으로 고려한다.
Fig 3에서 처럼 자전거와 오토바이는 시각적으로 유사하다. 때문에 두 class에 대한 score는 threshold를 넘지 못한다. 하지만 그들의 embedding이 "시각적으로 유사"하다고 판단되었기 때문에, 그들의 점수는 threshold를 가하기 전에 우선 더해진다. 합쳐진 점수가 threshold를 넘으면 샘플은 pseudo labeling에 쓰인다. pseudo label은 자전거와 오토바이의 embedding은 normalized class prediction score으로 weight되어 평균을 계산한다. 주어진 class label의 score를 얻고, clustering M에 의해 정의된 membership안에 있는 모든 멤버들의 normalized class score를 더한다. 이것은 group score \(g_{j}\)를 높인다. 그리고 mask를 가해 pseudo labeling을 위한 샘플들을 고른다. $$ \eta _{j}^{sc} = 1(max(g_{j})\geq\tau_{e})\ \ \ \ (4) $$만약 샘플이 pseudo labeling을 위해 선택되었다면, 해당 샘플들에 대해 그룹 멤버들의 embedding의 weighted average로 pseudo label embedding \(\hat{y}_{j}\)을 얻는다. 원래 class score인 \(p_{j}\)에 기반해 평균을 weight한다. 그리고 강한 augmentation을 준 \(u_{j}\)의 embedding prediction과 loss를 구한다. $$ L_{u}^{sc} = \frac{1}{\mu\cdot n}\sum_{j=1}^{\mu\cdot n}C(\hat{y}_{j},f_{sc}(A_{s}(u_{j})))\cdot \eta_{j}^{sc}\ \ \ \ (5) $$
One-Hot Classifier
전체적인 과정은 semantic classifier와 동일하지만, 두가지만 다르다. 1. cosine loss 대신 cross entropy loss를 사용한다. 2. confidence threshold로 비교하기 전에 label grouping을 적용하지 않는다. Supervised Loss는 $$ L_{s}^{oh} = \frac{1}{n}\sum_{i=1}^{n}H(y_{i},f_{oh}(x_{i}))\ \ \ \ (6) $$H는 cross entropy function을 나타낸다. Unsupervised Loss는 $$ L_{u}^{oh} = \frac{1}{\mu\cdot n}\sum_{j=1}^{\mu\cdot n}H(\hat{y}_{j},f_{oh}(A_{s}(u_{j})))\cdot \eta_{j}^{oh}\ \ \ \ (7) $$이다. \( \hat{y}_{j} = argmaxA_{w}(u_{j})\ ;\ \eta_{j}^{oh} = 1(max(\hat{y}_{j})\geq \tau_{o})\)이다. 두 종류의 loss function을 사용하는 것은 서로 다른 시각에서 학습하도록 하여 co-training을 돕는다.
Co-training Loss
두 개의 classifier가 서로를 보며 학습하도록 사용한다. classifier가 label을 보는 관점이 다르기 때문에 각각 unlabeled 데이터의 다른 샘플에 confident하다. 이를 이용해 만약 두 classifier들 중 하나가 그것의 예측에 대해 confident하다면 샘플을 가지고 있는다. 만약 두 classifier가 샘플에 대해 disagree한다면(각각 두 개의 다른 label에 대해 confident하는 등), 그 샘플은 각각 다른 pseudo label을 사용해 loss에 두 번 포함된다. 이런 경우 해당 샘플을 버리는 경우도 실험해 봤지만, 성능은 떨어졌다고 한다. Co-training Loss는 다음과 같이 정의한다.$$ L_{co} = \frac{1}{\mu\cdot n}\sum_{j=1}^{\mu\cdot n}C(M^{T}\hat{y}_{j}, f_{sc}(A_{s}(u_{j})))\cdot \eta_{j}^{oh}\ +\ H(argmax(p_{j}), f_{oh}(A_{s}(u_{j})))\cdot \eta_{j}^{sc}\ \ \ \ (8) $$ 최종적으로 Total Loss는 아래와 같다. $$ L_{total} = L_{s}^{sc}+L_{s}^{oh}+\lambda_{u}(L_{u}^{sc}+L_{u}^{oh})+\lambda_{co}L_{co}\ \ \ \ (9) $$\(lambda_{u}, lambda_{co}\)는 갈각 unsupervised loss와 co-training loss의 기여도를 조절하기 위한 고정된 scalar weight이다.
Extracting Label Semantics
본 논문에서는 Label embedding matrix M을 얻기 위한 두 방법을 제시한다. Label embedding matrix는 클래스들 간의 시각적 유사성에 대한 prior로 사용된다.
1. Knowledge graph를 사용하는 방법 Class label들이 semantic하게 의미있는 경우, Concept Net knowledge graph를 GloVe와 word2vec distributional embedding과 함께 사용해 distributional label embedding을 얻기 위한 basis로 사용한다. ConceptNet은 자연어 단어들을 labeled, weighted relation들로 연결해 multilingual knowledge graph로 만든다. 본 논문에서의 목표에 따라, graph가 시각적 유사성을 나타내는 관계들만 보유하도록 filter한다. GloVe와 word2vec은 유명한 word embedding set이다. 이 두 set은 다른 단어들 간의 distributional similarity는 파악하지만 visual similarity는 파악하지 못한다. 예를 들어, 'cat'과 'dog'라는 단어는 반려동물이라는 문맥에서 유사하게 등장하므로 GloVe나 Word2vec에서 유사한 word embedding을 가지지만, 이들이 시각적으로 유사하지는 않다. Distributional embedding을 ConceptNet filtered graph와 결합하여 이 문제를 해결한다. 이 과정에서 retrofitting이라는 방법이 사용된다. Retrofitting은 매 term마다 벡터의 원래 값과 가깝고, 동시에 graph에서의 term neighbor와 가까운 새로운 벡터를 찾으려는 object function을 사용한다. Retrofitting은 이 objective function을 최적화함으로써 knowledge graph에 기반한 word embedding matrix를 조절해나간다. 본 논문에서, 그래프에 있는 관계들은 시각적 유사성을 암시하기 때문에, retrofittng은 distributional similarity와 visual similarity 모두를 고려한 새 embedding hybrid set을 만든다. 마지막으로 embedding vocabulary에 존재하지 않는 class label들을 다루기 위해, fall out strategy를 사용해 가장 적절한 대안을 찾는다.
2. Class Attributes Annotations를 사용하는 방법 Class label들이 semantic하게 의미있지 않은 경우, manually annotated class attributes를 사용한다. 본 논문에서는 CUB-200 fine grained dataset의 attributes annotation을 M으로 사용했다고 한다. 데이터 instance를 annotating하는 것 보다 attribute를 annotate하는 것이 비용이 낮기 때문에 본 논문에서는 class attributes annotation을 제안한다고 한다.
Experiments
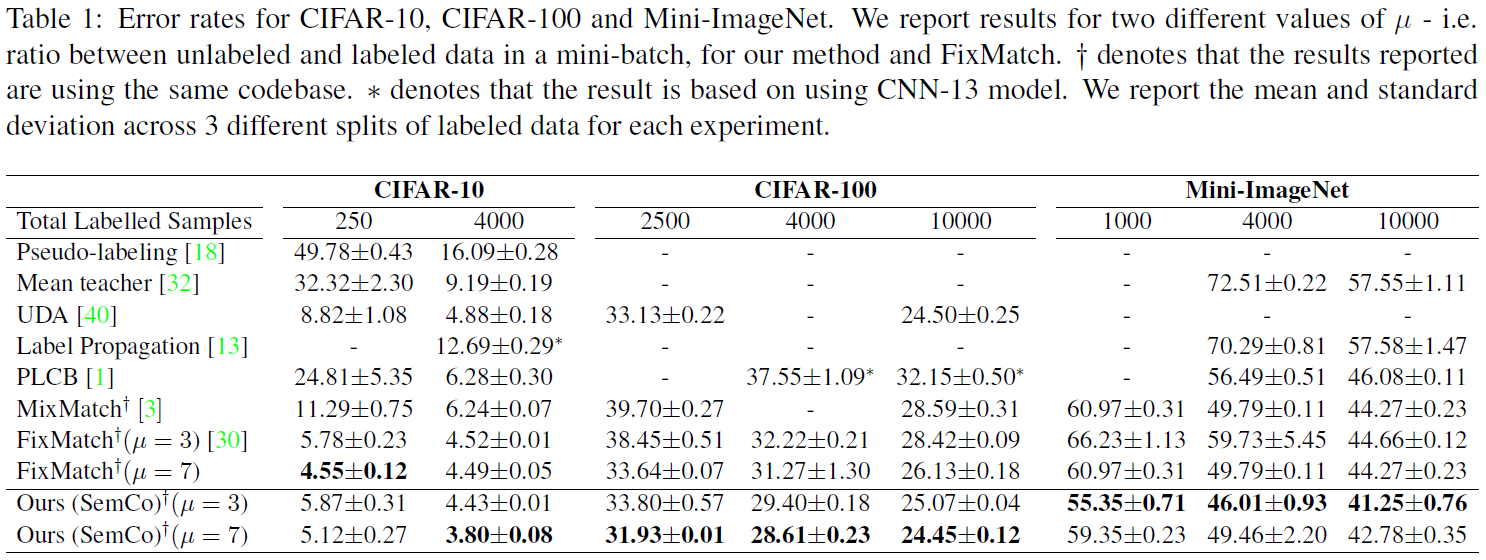
모든 실험 세팅에서 labeled set을 위한 샘플들의 수를 정하고, 나머지 샘플의 label은 무시하고 unlabeled 샘플로 사용했다고 한다. 그리고 consistency regularization 혹은 pseudo labeling을 사용하는 baseline들 간의 결과를 비교했다. 현실적인 비교를 위해, 이들의 방법을 codebase에 적용하고 모든 실험을 수행하기 위해 unified codebase를 사용했다. CIFAR 10/100에는 WideResnet 28-2를, Mini ImageNet에는 Resnet 18을, CUB 200과 DomainNet에는 Resnet 50을 사용했다. 그리고 인코더의 출력에 Fully Connected layer를 붙여 Semantic Classifier로 사용했다(Fig 1). 모델은 backbone 네트워크로 end to end로 학습시켰다(End to end란 입력과 출력만 보고 중간 과정(특징 추출 등)은 기계가 알아서 학습한다는 뜻. 머신러닝과 차별되는 딥러닝의 특징). 모든 실험에 동일한 파라미터를 사용했는데, \(\lambda_{u},\lambda_{co}\)의 값에는 민감하지 않고 \(\epsilon\) 값에는 민감했다고 한다. 모든 데이터셋의 labl은 semantic적으로 의미가 있으므로, 그들의 retrofitted embedding을 Semantic Classifier의 타겟으로 사용한다.
Table 3을 보면, Label grouping의 효과를 파악하기 위한 실험(clustering parameter \(\epsilon\) 조절)과, co-training의 효과를 파악하기 위한 실험(\(lambda_{co}\)를 적용하거나 안함으로써)을 진행했다. 결과를 보면 두 요인이 모두 성능에 중요한 영향을 끼친다고 하지만, co-training이 약간 더 중요하다고 한다.
또한, Table 4를 보면 CIFAR 100과 Mini ImageNet에서 두 개의 classifier들 모두에 대해 one hot 타겟을 사용해 보았다고 한다. 이 경우에 두 classifier의 차이점은 Semantic Classifier는 label grouping을 적용하지만 One Hot Classifier는 그렇지 않았다는 점이다. 두 classifier 모두에 one hot을 사용하면 성능이 떨어졌다고 한다. 이는 label에 대한 다른 관점으로 co-trianing을 진행하는 것이 도움이 된다는 것을 확인시켜준다.