[11654] Q : 알파벳 소문자, 대문자, 숫자 0~9 중 하나가 주어졌을 때, 주어진 글자의 아스키 코드값을 출력하는 프로그램을 작성해라
A :
[11720] Q : 첫 줄에 숫자의 개수가 주어진다. 둘째 줄에 숫자 N개가 공백없이 주어진다. 숫자 N개의 합을 출력해라
A :for i in x, tot+=int(i)로도 할 수 있다. 그리고 3번 줄에서 input()은 기본적으로 문자열을 받는다 생각하기 때문에 별도로 형을 바꿔줄 필요가 없다.
[10809] Q : 첫째 줄에 단어 S가 주어진다. 단어의 길이는 100을 넘지 않으며, 알파벳 소문자로만 이루어져 있다. a가 처음 등장하는 위치, b가 처음 등장하는 위치,...,z가 처음 등장하는 위치를 공백으로 구분해서 출력한다. 만약 어떤 알파벳이 단어에 포함되어 있지 않다면 -1을 출력한다. 단어의 첫번째 글자는 0번째 위치이다.
A :find() 함수는 S(문자열)안에 해당 문자(i)(chr)이 있는지 찾는다. 만약 있으면 그 문자가 첫 번째로 위치한 인덱스를 출력하고, 없으면 -1을 출력한다. 이 방법이 아니더라도, 5번 줄 부터 if i in S: print(S.index(i)), else: print(-1)으로 할 수도 있다. find와 index 함수는 공통적으로 문자열 안에서 문자의 위치를 찾는다. 그리고 (찾을 문자,시작점,종료점)의 입력이 공통적으로 가능하다. 숫자가 한 개이면 시작점, 2 개면 시작점과 종료점을 나타낸다. index('x',2)면 문자열의 둘째 위치부터 처음 'x'가 위치한 자리를 찾는 것이고, find('o',1,3)은 1~3번째 사이에 'o'가 위치한 자리를 찾는 것이다. 차이점은 find()는 찾는 값이 없을 경우 -1을 출력한다는 것이고, index()는 찾는 문자가 없을 경우 에러가 발생한다는 것이다. (https://ooyoung.tistory.com/78)
[2675] Q : 문자열 S를 입력받은 후에, 각 문자를 R번 반복해 새 문자열 P를 출력하는 프로그램을 작성해라. 첫 줄에 테스트 케이스틔 개수가 주어진다. 각 테스트 케이스는 반복횟수R, 문자열 S가 공백으로 구분되어 주어진다. 각 테스트케이스에 대해 P를 출력해라. 3 ABC => AAABBBCCC
A :4번 line에서 굳이 map을 안쓰고 input().split()만 써도 된다. 기본적으로 str 형태로 입력을 받기 때문. 그리고 map(input().split())만 시도해 보았으나, 이건 안된다. 그리고 위 코드는 S 속의 각 글자를 출력하는 것을 R번 반복하는 방식이다. 하지만 4번 line 뒤에 P=''을 두고, 6번 line 대신 P+=j*int(R)을 하고, 5번 line loop의 밖에서 print(P)를 해줘도 된다.
[1157] Q : 알파벳 대소문자로 이루어진 단어가 주어지면, 이 단어에서 가장 많이 사용된 알파벳을 대문자로 출력한다. 단, 가장 많이 사용된 알파벳이 여러 개 존재하는 경우엔 ?를 출력한다. 사용된 알파벳을 샐 때는 대소문자를 구분하지 않는다.
A :1번 line에서 str.upper() 함수는 문자열의 소문자와 대문자들을 모두 대문자로 바꿔준다. 6번 line에서 str.count() 함수는 해당 문자열에서 문자 i가 몇 번 등장하는지 알려준다. 9번 line에서도 list.count(max(cnt))는 cnt에서 가장 큰 값(index가 아님)이 list에 몇 번 등장하는지 세준다.
[1152] Q : 영어 대소문자와 공백으로 이루어진 문자열이 주어진다. 이 문자열의 단어 개수를 출력해라.
A :
[2908] Q : 두 수 A, B가 공백을 두고 주어진다. 두 수는 같지 않은 세 자리 수이며, 0이 포함되어 있지 않다. 이 중, 각 수의 자릿수를 뒤집은 것 중 큰 수를 출력해라
A :문자열에 [::-1]을 하면 거꾸로 뒤집는다.
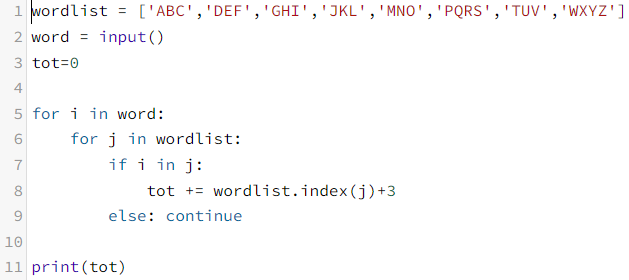
[5622] Q :숫자 1을 걸려면 총 2초가 필요하다. 1보다 큰 수를 거는데 걸리는 시간은 이보다 더 걸리며, 한 칸 옆에 있는 숫자를 걸기 위해선 1초씩 더 걸린다. 알파벳 대문자로 이루어진 단어가 주어지면, 다이얼을 걸기 위해 필요한 시간을 출력해라
A :
[2941] Q : 크로아티아 알파벳 변경
č
c=
ć
c-
dž
dz=
đ
d-
lj
lj
nj
nj
š
s=
ž
z=
전에는 크로아티아 알파벳을 입력할 수 없어서 다음과 같이 변경해서 입력했었다. 단어가 주어졌을 때, 몇 개의 크로아티아 알파벳으로 이루어져 있는지 출력해라
A : word.replace(i,'*')는 문자열에서 i를 찾아 *로 바꾼다. 이는 두 개 이상의 문자가 i에 들어가 있을 때도 사용된다. 2번 line에서 c=가 i에 들어가기도 하는데, 이런 경우 두 문자를 하나의 *로 바꾼다. ac=i가 a*i로 바뀌는 식이다.
[1316] Q : ccaazzzzbb는 c,a,z,b가 연속해서 나타나고, kin은 k,i,n이 연속해서 한 번만 나타나므로 그룹단어지만, aabbcccb는 b가 떨어져서 나타나므로 그룹 단어가 아니다. 첫째 줄에는 단어의 개수 N이 입력되고, 둘째 줄부터 줄을 바꿔가며 단어들이 들어온다. 그룹 단어의 수를 출력해라.
A : 이 문제에서 문자가 바뀌지 않은 경우는 그냥 넘어가도 된다. aabbcccc에서, i=0일 때는 word[i]==word[i+1]==a이므로 그냥 넘어간다. 하지만 i=1일 때는 a,b로 문자가 바뀌니, word[j+1:]에 해당 문자가 존재하는지 체크한다. 어차피 뒤에 a가 다시 등장하는지 아닌지는 모든 word[i]==a일 때마다 체크할 필요는 없다. 어차피 a가 연속되어 나왔다면, 한 번만 체크하면 되기 때문이다. line 9는 elif word[j] in word[j+1:]로도 쓸 수 있다. 이 문제에서는 cnt를 N에서 하나씩 줄여나가는 방식이 용이했다. 처음에는 cnt를 늘려나가는 방식을 사용했었지만, 이 문제에서는 word 속의 모든 문자들에 대해 뒤쪽에 중복이 한 번이라도 일어나는지 확인하는 알고리즘을 사용했다. 그것이 line 9인데, 구조상 에러가 나는 경우에 loop로 들어간다. 때문에 cnt를 줄여나가는 방식이 편하다. 때에 따라 cnt를 늘려가는 것만이 아닌, 줄여가는 것이 용이할 때도 있다.